Problem Set 4
This problem set is due on February 28, 2022 at 11:59am.
Step 1: Download this file locally.
%60%22%0A---%0A%0AThis problem set is due on February 28, 2022 at 11:59am.%0A%0A- **Name**:%0A- **UNCC ID**: %0A- **Other student worked with (optional)**:%0A%0A%23%23 Question 1%0A%0AThe first two problems are based on the same data. The data in %60data(foxes)%60 are 116 foxes from 30 different urban groups in England. %0A%0A%60%60%60%7Br warning=FALSE,message=FALSE%7D%0Alibrary(rethinking)%0Adata(foxes)%0Ad%3C- foxes%0Ahead(d)%0A%60%60%60%0A%0AThese fox groups are like street gangs. Group size (%60groupsize%60) varies from 2 to 8 individuals. Each group maintains its own (almost exclusive) urban territory. Some territories are larger than others. The %60area%60 variable encodes this information. Some territories also have more %60avgfood%60 than others. And food influences the %60weight%60 of each fox. Assume this DAG:%0A%0A%60%60%60%7Br fig.height=4, fig.width=4%7D%0Alibrary(dagitty)%0A%0Ag %3C- dagitty('dag %7B%0Abb=%220,0,1,1%22%0AA %5Bpos=%220.450,0.290%22%5D%0AF %5Bexposure,pos=%220.333,0.490%22%5D%0AG %5Bpos=%220.539,0.495%22%5D%0AW %5Boutcome,pos=%220.445,0.686%22%5D%0AA -%3E F%0AF -%3E G%0AF -%3E W%0AG -%3E W%0A%7D%0A%0A')%0Aplot(g)%0A%60%60%60%0A%0Awhere F is %60avgfood%60, G is %60groupsize%60, A is %60area%60, and W is %60weight%60.%0A%0A**Part 1**: Use the backdoor criterion and estimate the total causal influence of A on F. %0A%0A%60%60%60%7Br eval=FALSE, include=FALSE%7D%0A%23 type in your code here%0A%0A%60%60%60%0A%0A**Part 2**: What effect would increasing the area of a territory have on the amount of food inside it?%0A%0A%5BWrite answer here in sentences%5D%0A%0A%23%23 Question 2%0A%0ANow infer both the **total** and **direct** causal effects of adding food F to a territory on the weight W of foxes. Which covariates do you need to adjust for in each case? In light of your estimates from this problem and the previous one, what do you think is going on with these foxes? Feel free to speculate%E2%80%94all that matters is that you justify your speculation.%0A%0A%0A%0A%60%60%60%7Br eval=FALSE, include=FALSE%7D%0A%23 Total causal effect: type in your code here%0A%0A%60%60%60%0A%0A%0A%0A%60%60%60%7Br eval=FALSE, include=FALSE%7D%0A%23 For the direct causal effect: type in your code here%0A%0A%60%60%60%0A%0A%23%23 Question 3%0A%0AReconsider the Table 2 Fallacy example (from Lecture 6), this time with an unobserved confound U that influences both smoking S and stroke Y. Here%E2%80%99s the modified DAG:%0A%0A%60%60%60%7Br echo=FALSE, out.width = '50%25'%7D%0A%23 run this chunk to view the image%0Aknitr::include_graphics(%22https://raw.githubusercontent.com/wesslen/dsba6010-spring2022/master/static/img/assignments/04-problem-set/04-problem-set-0.png%22)%0A%60%60%60%0A%0APart 1: use the backdoor criterion to determine an adjustment set that allows you to estimate the causal effect of X on Y, i.e. P(Y%7Cdo(X)). %0A%0AFor this exercise, you can use %5Bdagitty.net%5D(http://www.dagitty.net/dags.html).%0A%0AStep 1: Input your DAG into Dagitty.net and copy/paste your results here:%0A%0A%60%60%60%7Br eval=FALSE%7D%0A%23 insert code here%0A%0Ag %3C- dagitty('%0A %23 copy/paste dagitty.net code for DAG here%0A ')%0A%60%60%60%0A%0AStep 2: What is the adjustment set to estimate the causal effect of X on Y?%0A%0A%60%60%60%7Br eval=FALSE, include=FALSE%7D%0A%23 find adjustment set: type in your code here%0A%0A%60%60%60%0A%0APart 2: Explain the proper interpretation of each coefficient implied by the regression model that corresponds to the adjustment set. Which coefficients (slopes) are causal and which are not? There is no need to fit any models. Just think through the implications.%0A%0A%5BWrite answer here in sentences%5D){kind=link}
Step 2: Complete the assignment
Step 3: Knit the assignment as either an html or pdf file.
Step 4: Submit your file here through this canvas link.
- Name:
- UNCC ID:
- Other student worked with (optional):
Question 1
The first two problems are based on the same data. The data in data(foxes) are 116 foxes from 30 different urban groups in England.
library(rethinking)
data(foxes)
d<- foxes
head(d)
## group avgfood groupsize area weight
## 1 1 0.37 2 1.09 5.02
## 2 1 0.37 2 1.09 2.84
## 3 2 0.53 2 2.05 5.33
## 4 2 0.53 2 2.05 6.07
## 5 3 0.49 2 2.12 5.85
## 6 3 0.49 2 2.12 3.25
These fox groups are like street gangs. Group size (groupsize) varies from 2 to 8 individuals. Each group maintains its own (almost exclusive) urban territory. Some territories are larger than others. The area variable encodes this information. Some territories also have more avgfood than others. And food influences the weight of each fox. Assume this DAG:
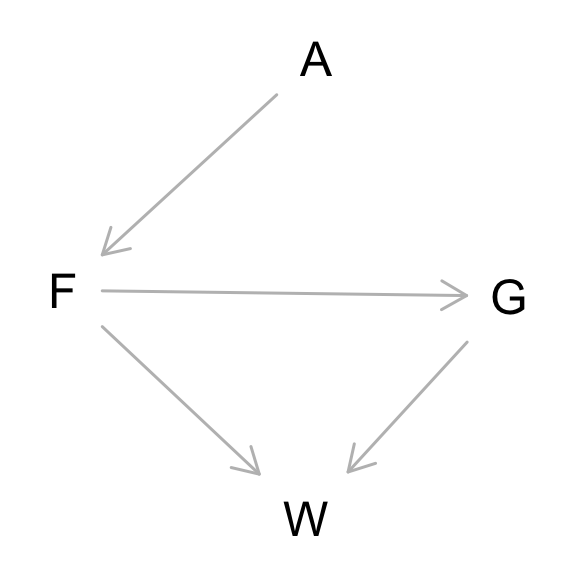
where F is avgfood, G is groupsize, A is area, and W is weight.
Part 1: Use the backdoor criterion and estimate the total causal influence of A on F.
Part 2: What effect would increasing the area of a territory have on the amount of food inside it?
[Write answer here in sentences]
Question 2
Now infer both the total and direct causal effects of adding food F to a territory on the weight W of foxes. Which covariates do you need to adjust for in each case? In light of your estimates from this problem and the previous one, what do you think is going on with these foxes? Feel free to speculate—all that matters is that you justify your speculation.
Question 3
Reconsider the Table 2 Fallacy example (from Lecture 6), this time with an unobserved confound U that influences both smoking S and stroke Y. Here’s the modified DAG:
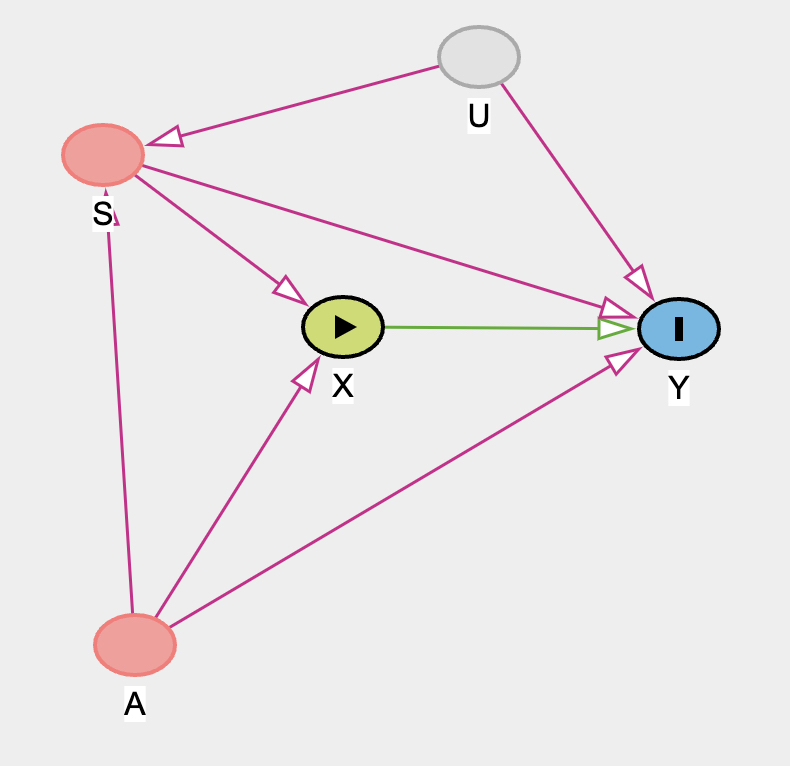
Part 1: use the backdoor criterion to determine an adjustment set that allows you to estimate the causal effect of X on Y, i.e. P(Y|do(X)).
For this exercise, you can use dagitty.net.
Step 1: Input your DAG into Dagitty.net and copy/paste your results here:
# insert code here
g <- dagitty('
# copy/paste dagitty.net code for DAG here
')
Step 2: What is the adjustment set to estimate the causal effect of X on Y?
Part 2: Explain the proper interpretation of each coefficient implied by the regression model that corresponds to the adjustment set. Which coefficients (slopes) are causal and which are not? There is no need to fit any models. Just think through the implications.
[Write answer here in sentences]